Firestoreのセキュリティルールでは、文字列を正規表現で制限することができます。悪意のあるユーザにおかしな値を登録されないようアプリと同じ制限をかけておきましょう。
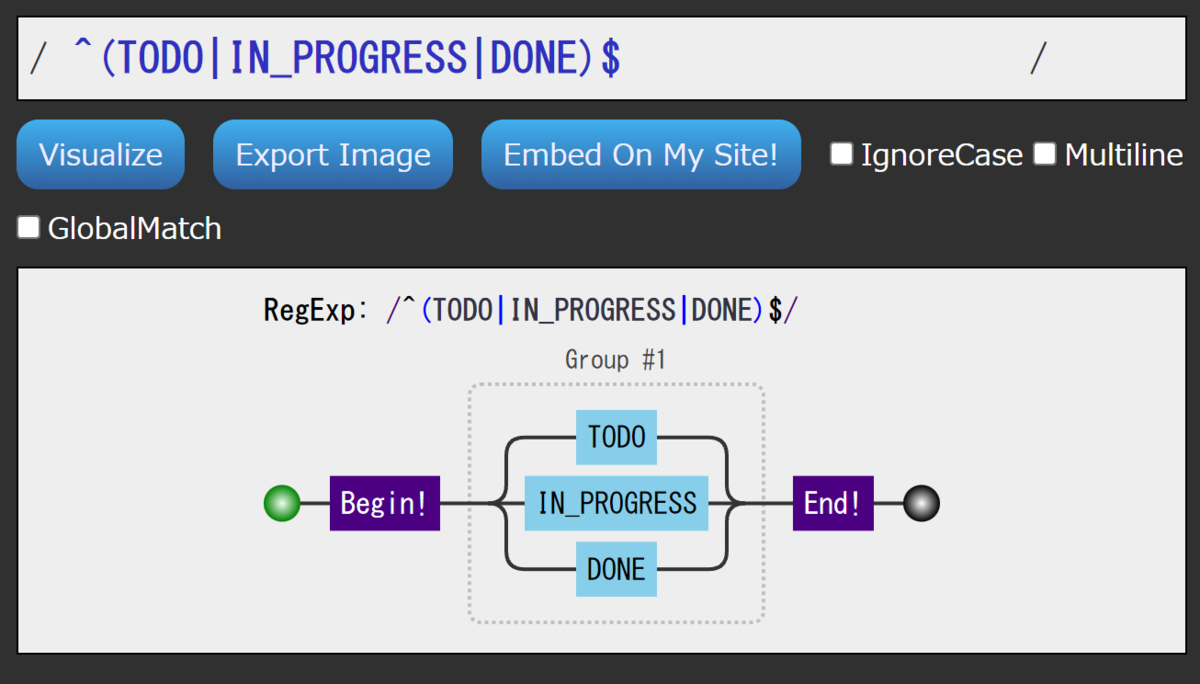
String.matches(regex)
String.matchesを使うと、フィールドに登録される値が 指定された正規表現を満たす場合にのみ、DBに登録することができます。 記述はこのようになります。
// 電話番号(ハイフンなし)
allow create, update: if request.resource.data.tel.matches("^0[0-9]{9,10}$")
// メールアドレスっぽい文字列
// size()も組み合わせて使いましょう
allow create, update: if request.resource.data.email.matches("^[-a-zA-Z0-9_\\.]+@[-a-zA-Z0-9_\\.]+$") &&
request.resource.data.email.size() <= 255
String.matches()の使用例
例として参加登録フォームを作ってみます。
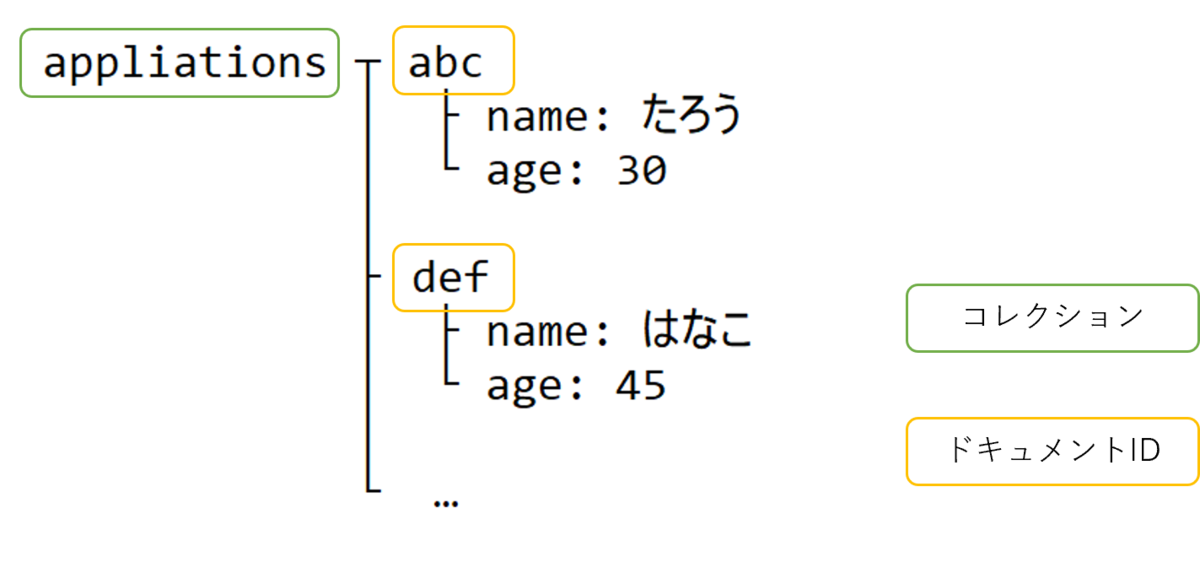
データ構造はこのようになっています。
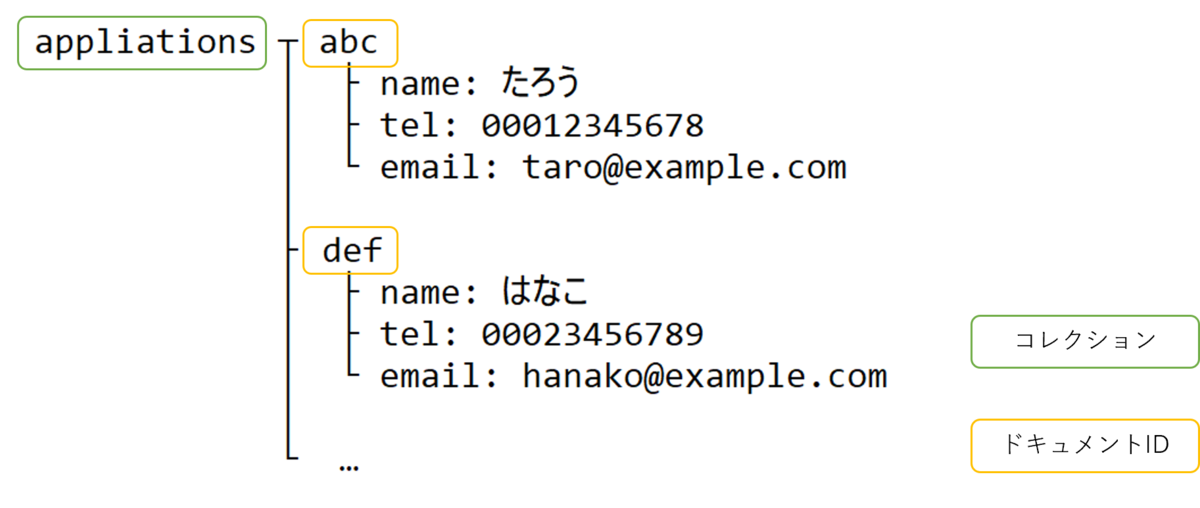
電話番号は0とそれに続く数字が9個か10個です。メールアドレスは半角英数と、記号は-_.が使えます。@マークは1つだけです。
セキュリティルールの全体はこのようになります。
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /applications/{application} {
function validApplication(docData) {
return docData.tel.matches("^0[0-9]{9,10}$") &&
docData.email.matches("^[-a-zA-Z0-9_\\.]+@[-a-zA-Z0-9_\\.]+$") &&
docData.email.size() <= 255;
}
allow create, update: if validApplication(request.resource.data)
}
}
}
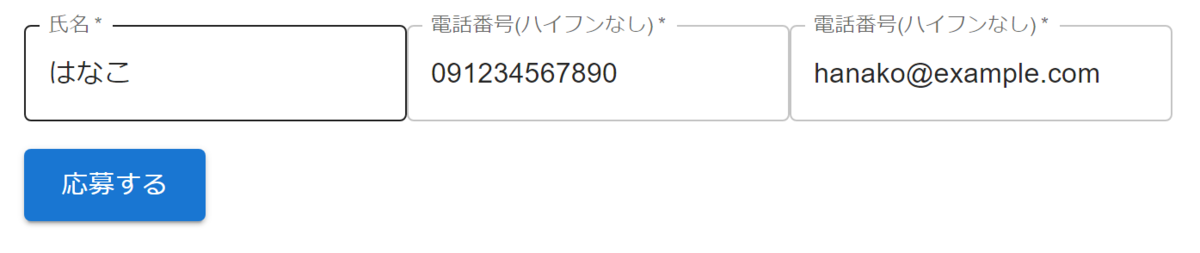
正規表現に合うように登録してみます。
Firebaseのコンソールで確認すると登録されていることが分かります。

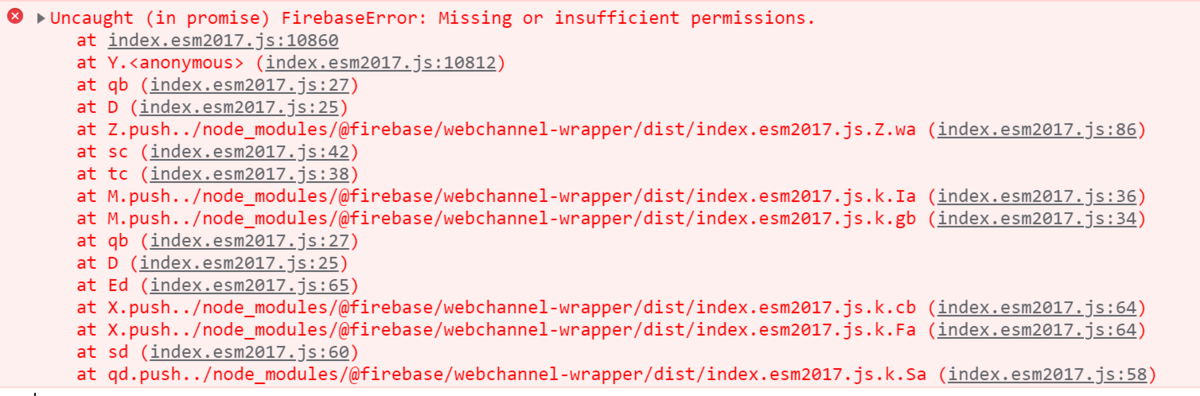
電話番号を12桁で登録してみます。
エラーになり、コンソールを確認すると登録されていないことが分かります。
次に、メールアドレスに使えない文字列を使ってみます。
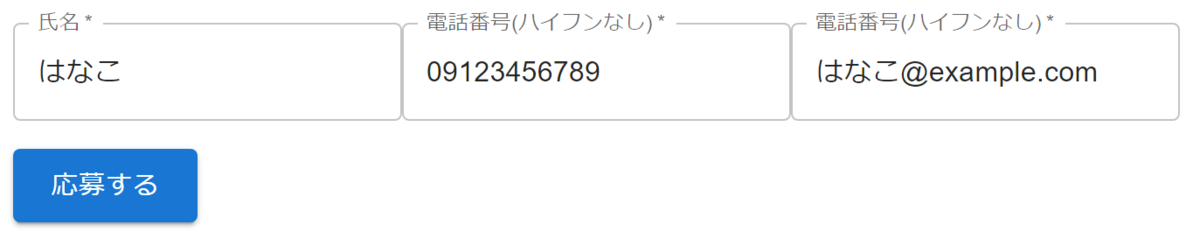
こちらもエラーになり、コンソールを確認すると登録されていないことが分かります。